Table of contents
Code | Arxiv(2303) | ProjPage
Briefs
Author’s Talk
Source Video: 【Talk | ICLR'23 Oral 美国东北大学马旭:图像亦是点集(Image as Set of Points)】
Insights:
-
Use clustering to extract image features.
-
Fusing cluster members through Collapse followed by Reconstruction
Paper Explain
Source Video: 【ICLR 2023】Image as Set of Points.计算机视觉新范式,利用聚类的思想实现图像建模。在多个下游任务上不输ViT和ConvNets】
- Image features are refined through multiple aggregation and dispatching using attention for pixels.
Paper Notes
Abstract
-
Is the picture natively well-clustered?
-
If so, this method essentially is same as convolution, which extracts features by fusing pixels in the kernel.
But Cluster is discreate and sparse, can it capture high-level feature?
-
-
Clusters appeals to segmentation and interpretability.
Intro
-
Is this method designed for a single image?
However, MVS can directly leverage epipolar lines on source views more concisely, without fusing neighbor pixels features..
-
Pixels with same color can imply fundamentally difference?
“Similar pixels are grouped, but they are fundamentally different.” ?
I think same color means rays hit same spatial geometry.
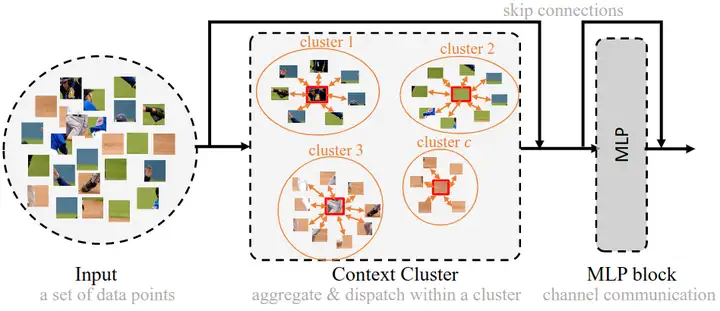
Method
Pipeline:
-
Initial feature of raw pixels are 5-D, including color (r,g,b) ∈ [0,255] and normalized pixel center (x,y) ∈ [0, 1]-0.5
-
Pixels are reduced to 𝑟 times at each stage’s start by fusing k (=4 or 9) neighbors around the 𝑟 evenly distributed anchors across the image, i.e., concatenating their channels and projecting to specified dimension by FC, unlike maxpooling.
-
Conv layer can perform points reduction as well if points’ organization aligned with the raw image.
-
In their implementation, function
PointReduceruses a conv layer instead of FC.For model
coc_base_dim64, before stage-0, image is reduced to 1/16 with kernels of size=4, i.e., 16 points are fused to 1. and 5-D features are mixed to 64-D.1 2# Point Reducer is implemented by a layer of conv since it is mathmatically equal. nn.Conv2d(5, 64, kernel_size=4, stride=4, padding=0)
-
-
Output points require reording for downstream pixel-wise tasks, like segmentation.
CoC Block:
Each stage repeats Context Cluster block several time. A blocks processes points set in 3 steps:
-
Pixels clustered $c$ groups in the feature space
-
c centers are evenly distributed and form voronoi based on the cosine similarity of each point to each center feature.
-
Centers are chose through
nn.AdaptiveAvgPool2d((proposal_w, proposal_h)), which will set kernel and stride automatically for AvgPool2d.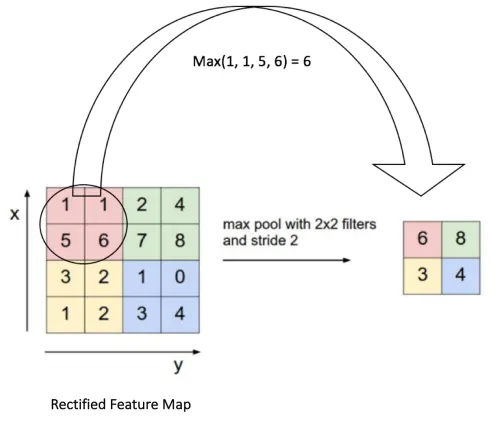
-
Center feature is the average of k nearest neighbors, after placing the c centers.
-
Intial features are 5-D including RGB and position (x,y).
-
-
Aggregation: Add features of all members to an aggregated feature g:
$$g = \frac{1}{C} (v_c + ∑_{i=1}^m sig(α s_i + β) * v_i )$$The aggregated feature g is computed by plusing center’s feature and the weighted sum of feature vectors of all m points vᵢ in a cluster, scaled by a tunable factor $sig(α sᵢ + β)$ ∈ (0,1), where s is similarity to the center feature and α,β are nn.parameters.
The denominator $C = 1+ ∑_{i=1}^m sig(α sᵢ+ β)$ aims to limit the magnitude.
-
Dispatching: Each member updates its feature from the aggregated feature, so as to fuse all other points and realize spatial interaction.
$$p_i' = p_i + FC(sig (α sᵢ+ β) * g )$$The amount of g assigned to a member is determined by the adaptive similarity again, inversing the summation.
-
Communication between pixel in a cluster is like server-client in a centralized network.
-
Centers’s positions are fixed for efficiency, so it emphasizes locality.
-
doubt: Advanced postional embedding could be applied.
-
doubt: Will different selection strategies affect model performance? They mentioned Farthest Point Sampling (FPS) mehtod in appx.D
Architecture:
Context Cluster is a hierarchical model composed 4 stages and points are reduced to 1/4 (ie, h/2, w/2) after each stage.

Play
Model can be comprehended by debugging the file “context_cluster”, using environment of “AIM”.
\begin{algorithm}
\begin{algorithmic}
\STATE PointReducer: Conv2d(x), downsample 16 times, 256 dim
\STATE Partition feature maps: rearrange(x)
\STATE Centers feature from x: AdaptiveAvgPool2d((2,2))(x)
\STATE Simlarity matrix: vectors' inner product with multi-head
\STATE Clustering: .scatter\_
\STATE Aggregate feature $g$: sum members' feat based on similarity
\STATE Dispatch $g$ to members
\STATE Reverse partition
\STATE Project to out\_dim: Conv2d
\STATE FFN: Mlp, out\_dim → hidden → out\_dim
\end{algorithmic}
\end{algorithm}
Similarity and points’ features are optimized separately:
-
Similarity: x →
center→sim -
Features: x →
value→val_center→ aggregated featureout
sim and out are decoupled.