Table of contents
Notes
Abstract
(2023-05-24)
-
Model the radiance field as a 4D tensor.
- Optimize a 4D tensor?
- Optimize a 4D matrix?
- MLP (network) is a 2D matrix? 𝐗 @ 𝐖ᵀ = 𝐘;
- Nonlinear regession cannot be solved by linear algebra?
- Gauss-Newton algorithm
- Nonlinear regession cannot be solved by linear algebra?
(2023-05-29)
Terminology:
-
“4D scene tensor”: (x, y, z, feature). Each voxel is allocated with a sigma and appearance feature. (Alike a feature field?).
- (2023-10-19) Features on each point derived from the coefficients of each vector in each basis.
-
“factorize”: Encode the data into “coordinates” (coefficients) in the principle components;
-
“multiple compact”: Principle components are orthogonal between each other;
-
“low-rank”:
The number of principle components is small.Rank=1 is a vector, rank>1 will depend on the rank of the matrix; -
“component”: The most “iconic sample”, which can be reshaped (reconstructed) to a data that has the original dimensionality,
-
In other words, it’s a “space” constituted by several directions; e.g., an image space has X and Y 2 directions.
-
In TensoRF, a vec + a mat is a component.
-
For a scene placed in a cube, one of components is an equal-sized cube, and the 3 directions are the X,Y,Z axes.
(2023-10-19) Because the scene is the reconstruction goal, it served as the template of each basis. If the scene isn’t be reconstructed directly, for example, reconstring each ray (ro,rd,l,s), what’s the basis then?
A 1D signal’s basis is sin+cos.
-
(2023-10-19) Voxels are discrete samples from a continuous scene function. Coefficients on vectors of a basis are inner product between the scene function and each basis. Given some sample points (voxels), their coefficients are the coordinates of their projection onto the basis.
-
-
“mode”: A principle component, a coordinate system, a space, a pattern;
Introduction
-
“CAN-DECOMP/PARA-FAC”: Every direction in a component is a 1-dimensional vector.
-
“Vector-matrix decomposition”: two directions out of 3 are jointly represented by a “frame” (plane),
So the obtained factors for 1 component are 1 vector and 1 matrix.

-
VM decomposition spends more computation for more expressive components.
The “similarity” is computed “frame-by-frame”, so it needs more calculation. And the original structure is more kept than 2 dimensions are analyzed individually, so the components could be more representitive and less components are needed.
-
Better space complexity: O(n) with CP or O(n²) with VM,
Comparing with optimizing each voxel directly, which is O(n³), optimizing factors takes less memory.
-
Gradient descent
They’re not encoding the radiance field into factors because the feature grid/tensor is unknown. They decompose the feature grid to simplify the optimization, which then turns to optimizing factors.
Implementation
A scene is a radiance field.
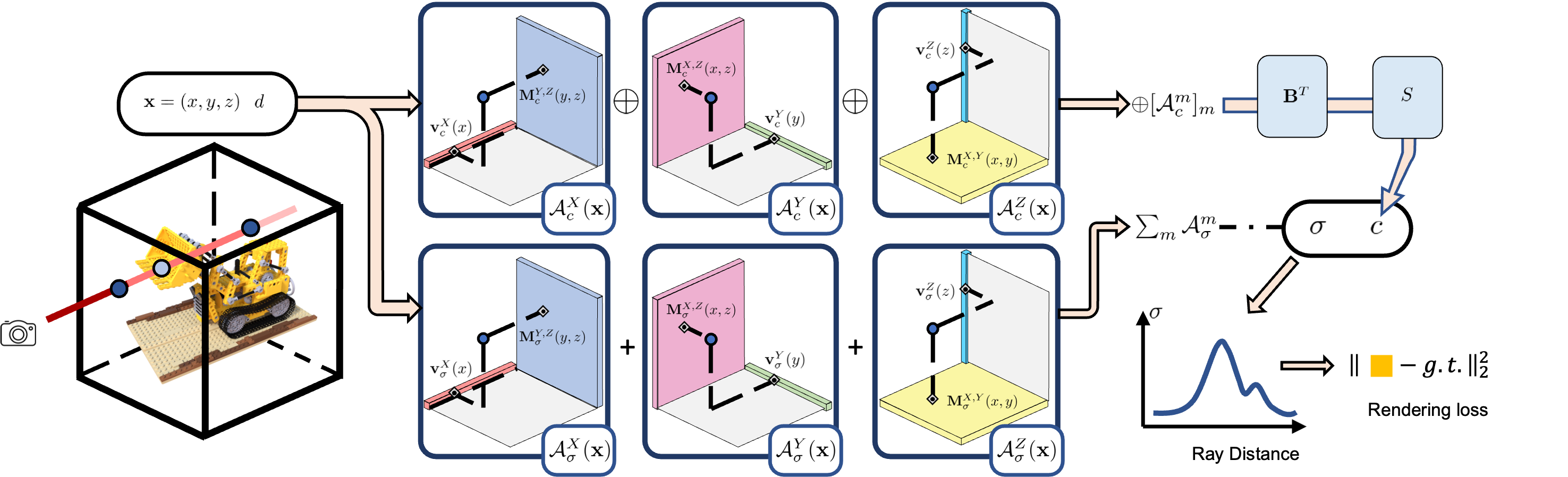
Radiance field (4D tensor) = Volume density grid (3D tensor: X,Y,Z) + Appearance feature grid (4D tensor: X,Y,Z,feat)
-
Radiance field is a tensor of (X,Y,Z,σ+feature), where volume density σ is 1D, appearance feature is 27D;
-
1D Volume density (feature) is decomposed to 3 vectors (CP) or 3 vector-matrix combo (VM) for each component.
-
27D Appearance feature is amortized into 3 vector-matrix combos for 16 components.
-
These components are coefficients to fuse the
data“basis vectors” in different ways, which is acting like a network. -
1D density and 27D features are optimized jointly with coefficients.
- (2023-10-28) Features and coefficients are optimized simultaneously.
where S is two-layer MLP: 150 → 128 → 128 → 3
- (2023-10-28) I guess the authors came up with tensor decomposition because they realized that Positional Encoding is Fourier decomposition, And NeRF then used MLP to learn the coefficients for the decomposed “Fourier basis”: sin and cos.
Interpolate vector & matrix
Instead of performing tri-linear interpolation at a point by computing 8 corners, a point at arbitrary position is computed by interpolating th vector and matrix.
Code Notes
Steps overview
-
Dataset includes
all_rgbsand correspondingro, and normalizedrdunder world spaceall_rays, (N_imgs×H×W, 3) -
Split the bounding box $[^{[-1.5, -1.5,\ -1.5]}_{[1.5,\quad 1.5,\quad 1.5]}]$ into a voxel grid of the given resolution
[128,128,128]determined by the number of voxelsargs.N_voxel_init1reso_cur = N_to_reso(args.N_voxel_init, aabb)Sampling number
nSamples= voxel grid diagnoal ∛(128²+128²+128²) / stepSize
Learnable Parameters
init_svd_volume() creates basis vectors and matrices.
A vector and a matrix are orthogonal because they’re a side and a plane of a cube.
Parameters to be optimized: 3 Vectors and 3 Matrices
|
|
Given a 3D tensor, it can be decomposed as Vector-Matrix combo in three directions:
Each direction has 16 components. In other words, an observation of the cube from a direction can be reconstructed by summing those components up.
doubt: These 3 directions are orthogonal because the cube is viewed from distinct directions, but how are those 16 channels guaranteed to be orthogonal?
- (2023-10-17) Based on the theory of PCA?
- (2023-10-28) Is it possible that 16 components are parallel instead of orthogonal? They’re summed directly, similar to an FC layer with 16 neurons representing 16 ways of combining features.
doubt: Are those components parallel to each other? Do they have different importance or priority?
- (2023-06-22) I guess no. They’re just added together simply.
A scene is decomposed to a set of components, then a scene can be reconstructed using a set of coefficients of those components.
Sepcificlly, each voxel is a summation of the products for corresponding projections on vector and matrix in 3 directions and 16 components.
Based on those vector-matrix components, with the help of interpolation, the value at any location can be obtained.
Filtering rays
Filter the effective rays based on the ratio (deviation) betweem the direction of rays and the direction of bounding box corners.
Mask those rays inside bbox by compareing the ratio of the rd to the direction of the two bbox corners:
|
|
An effective ray should end up inside the bounding box,
✩ is an effective ray, while ◯ is a non-effective ray because it’s out of the bbox.
Reconstruct sigma
The sigma value on each voxel is the summation of 16 components of all 3 directions.
|
|
The factors grid is composed of 3 planes self.density_plane and 3 vectors self.density_line
The factors corresponding to the sampled 3D points are obtained by F.grid_sample():
Retrieve the “factor in the vector direction” for each sample voxel is like the above figure right.
doubt: Were the coefficients not multiplied with basis vector, but simply summed up together as the reconstruction?
-
(2023-06-29) TensoRF is not projecting voxel onto each basis vector (matrix), but retrieving the coefficients from the factor grid.
What the TensoRF retrieved is the coefficient * vector because it samples the factor grid directly. The factor grid satifies orthogonality naturally, so a coefficient inside is equivalent to having already multiplied with basis vectors.
Reconstruct appear. feature
For appearance feature of each voxel, the vector projection and matrix projection in 3 directions are concatenated together, then multiply together:
|
|
Then RGB is mapped from the appearance featrue:
Optimizing
The learnable parameters includes:
- 16 vectors and 16 matrices for density in 3 directions;
- 48 vec and 48 mat for app feature in 3 directions;
- linear layer transforming 48x3 dim appearance feat to 27D;
- linear layer mapping 27D feat+viewdir to 3-dim rgb.
by aggregating its components") b("Use BP+GD (Adam) to
optimize those parameters") x --> y --> b
Losses: L2 rendering loss + L1 norm loss + Total Variation loss.
- TV loss benefits real datasets with few input images, like LLFF.
Q&A
- How does it ensure that the components are orthogonal during training? (2023-06-10)