Table of contents
(2023-07-28)
taku
Source video: 你必须拥有RWKV,以及其他模型为何拉胯,NLP杂谈 - taku的交错电台 - bilibili
-
Sequentially generating mimics the human speaking behavior naturally;
-
No need to perform Positional Encoding, RNN won’t mess up the order of tokens,
- because the next token always derives from the previous hidden state;
- RNN internally has time order.
- Vanilla transformer doesn’t include Positional Encoding.
-
Cannot generate a sentence parallelly, but only word-by-word,
- because the “fusion matrix multiplication”, i.e.,
attn @ Vhas simplied to a RNN;
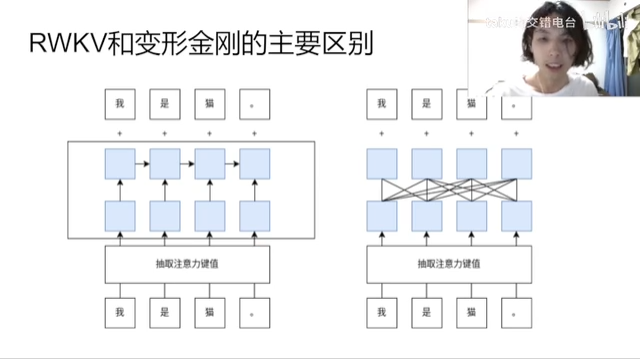
- because the “fusion matrix multiplication”, i.e.,
-
Less multiplication: RNN module only consider previous two hidden states;
- And the matmul of Q*V and feedfoward module are kept.
-
Locally optimizing can be done by giving a hidden state.
-
Transformer has the ultimate precision because it attends all the token in the sequence, but it’s not necessary if the required performance can be met in some way.
- RWKV may forget former tokens along inputting.
-
RWKV is good for inference and Transformer is good for training.
-
RWKV incorporates RNN into transformer;
-
Such that RNN is combined with residual connection: hidden_state = hidden_state + attention(hidden_state)
-
Previous RNN is combine with attention but without residual connection;
-
Transformer is attention + residual
-
-
RWKV has a consistent memory cost at inference,
-
because each generation only attends to the last two hidden states. That means it can accept infinite-long sequence when inference.?
-
However, the memory cost grows up linearly when tranining, because the intermediate hidden states are required to store for calculating gradients.
-
Su, Jianlin
Source article: Google新作试图“复活”RNN:RNN能否再次辉煌?- 苏剑林
-
Only if the sequence length is significantly longer than hidden size, the standard attention will become slower quickly because its quadratic complexity. Otherwise, it’s almost linear complexity. So, it’s not necessary to make attention linear.
-
On LM (Language Model) tasks, RNN underperform attention may suffer from the hidden size.
Yannic Kilcher
Source video: RWKV: Reinventing RNNs for the Transformer Era (Paper Explained) - Yannic Kilcher