
watch: CppExt - AI葵 01 | Cpp Bridges PyTorch & CUDA
Source video: Pytorch+cpp/cuda extension 教學 tutorial 1 - English CC -
Instructions
The pure purpose of CUDA extensions is to make PyTorch programs faster.
CUDA extensions are more efficient than PyTorch in two scenarios:
-
Procedures can’t be executed in parallel, e.g., each ray has different numbers of points.
-
Many sequential computations, like a nn.Sequential module including lots of conv layers. C++ can fuse multiple layers to a single function.
Relations: PyTorch will call a C++ function, which will call the CUDA extension.
Environment
-
conda create -n cppcuda python=3.8 -
Latest PyTorch:
conda install pytorch==1.12.1 cudatoolkit=10.2 -c pytorchVersion of the (compiled) PyTorch needs to match the local CUDA version (checked by
nvcc -V). -
Upgrade pip for building cpp programs:
python -m pip install pip -U
Pybind11
The code: “interpolation.cpp” acts like the main function that calls the C++ function, and python will call the “main” function.
The “main” function receives input tensors from PyTorch and
return output tensors from CUDA code.
|
|
-
(2023-10-18) Didn’t update the includePath for PyTorch as follows because I didn’t find the entry “C/C++: Edit Configurations (JSON)” after pressing F1. It seems like VSCode finds PyTorch automatically.
1 2 3 4 5 6"includePath": [ "${workspaceFolder}/**", "/home/yi/anaconda3/envs/AIkui/include/python3.10", "/home/yi/anaconda3/envs/AIkui/lib/python3.10/site-packages/torch/include", "/home/yi/anaconda3/envs/AIkui/lib/python3.10/site-packages/torch/include/torch/csrc/api/include" ], -
(2023-10-27) However, error intellisense occurs after I installed the ‘C/C++ Extension Pack’ for VSCode. So setting
includePathis necessary. -
pybind11 connects Python and C++11 codes.
1 2pip install pybind11 pip install ninja
Pip compile
Build the cpp codes to a python package.
-
Create a “setup.py” for building settings.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19from setuptools import setup from torch.utils.cpp_extension import BuildExtension, CppExtension setup( name="my_cppcuda_pkg", # python package name version="0.1", description="cppcuda example", long_description="cpp-cuda extension", author="z", author_email="luckily1640@gmail.com", ext_modules=[ CppExtension( name='my_cppcuda_pkg', sources=["interpolation.cpp",]) # code files ], cmdclass={ # commands to be executed "build_ext":BuildExtension } ) -
Build and install the package:
1 2 3 4pip install . # setup.py path is cwd (since pip 21.3) # Or adding an arg to avoid the deprecation warning: pip install . --use-feature=in-tree-build
(2024-03-06) Pybind11 module also can be compiled with cmake: 如何在Python中调用C++代码?pybind11极简教程 - HexUp
PyTorch Call
“test.py” will call the cpp program.
- Package
torchmust to be imported before the cuda extensions.
|
|
title: “watch: CppExt - AI葵 02 | Kernel Function” date: 2023-10-23T20:20:00
-
Source video: Pytorch+cpp/cuda extension 教學 tutorial 2 - English CC -
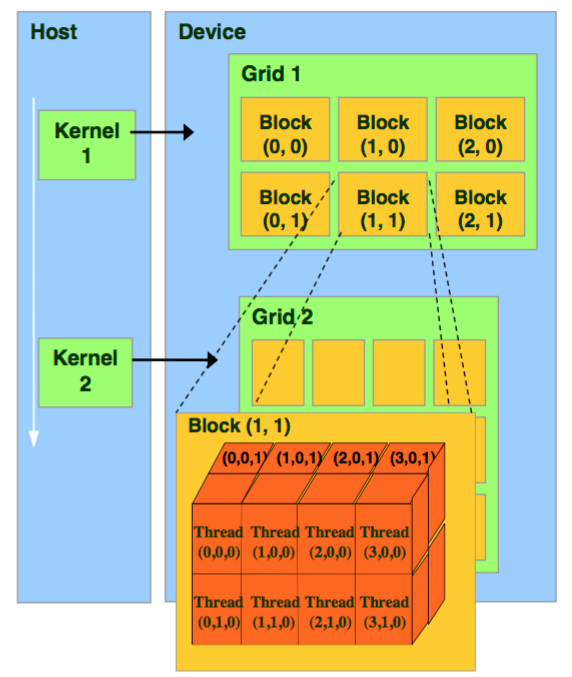
GPU Parallsiam
Kernel → Grid → Block → Thread
-
A thread is the smallest computation unit that executes element arithmatic independently.
-
The number of threads in a block is limited up to 1024. To multiply the amount of threads, many Block are placed together in a Grid. Docs
The number of Blocks can be $(2^{31}-1) × 2^{16} × 2^{16}$
-
Trilinear Interpolate
Each corner is sumed up with a weight which is the product of normalized distance from the point to the opposite side.
-
Analogy to Bilinear interpolation:
$$\rm f(u,v) = (1-u)(1-v)⋅f₁ + u(1-v)⋅f₂ + (1-u)v⋅f₃ +uv⋅f₄$$
-
For Trilinear interpolation, each weight is the product of 3 normalized distances to the opposite plane.
$$ \begin{aligned} \rm f(u,v,w) =& (1-u)(1-v)(1-w)f₁ + u(1-v)(1-w)f₂ + (1-u)v(1-w)f₃ + uv(1-w)f₄ \\ &+ (1-u)(1-v)w f₅ + u(1-v)w f₆ + (1-u)vw f₇ + uvwf₈ \\ & \\ =&\rm (1-u) [ (1-v)(1-w)f₁ + v(1-w)f₃ +(1-v)wf₅ +vw f₇ ] \\ &\rm + u [ (1-v)(1-w)f₂ + v(1-w)f₄ + (1-v)w f₆ + vwf₈] \end{aligned} $$
Input-Output
-
Input: features (N, 8, F) and points coordinates in each cube (N, 3)
Output: features at points (N, F).
-
Operations can be performed in parallel
- Each point can be computed individually;
- Each feature can be computed individually.
Code
Notes:
-
If input variables of CUDA kernel are torch.Tensor, they must be checked whether they’re on cuda and contiguous, because threads needs to read/write data without jumping.
While if input variables are not tensor, the checking is not required.
cpp
Cpp: “trilinear_interpolate.cpp”
|
|
header
Header: “include/utils.h”
|
|
cu
CUDA kernel: “interpolation_kernel.cu”
- Source video: part-3
- Source code
|
|
-
Since 2 dimensions of the output tensor both require parallism, 256 threads in a block are resized to a square of (16, 16).
-
To ensure each element of the output tensor assigned with a thread, 2 by 1 (2,1) blocks are required.
Such that each element will be computed by a thread (“box”) individually.
Notes:
-
threads and blocks are not assigned with tuples:
1 2const dim3 threads = (16, 16, 1); // total 256. const dim3 blocks = ( (N+threads.x-1)/threads.x, (F+threads.y-1)/threads.y )They’re object instantiated from classes:
1 2const dim3 threads(16, 16, 1); // total 256. const dim3 blocks( (N+threads.x-1)/threads.x, (F+threads.y-1)/threads.y ) -
If multiple tensors need return, the return type of the func should be
std::vector<torch::Tensor>. And the end syntax:return {feat_interp, points};
- pytorch.org/cppdocs/
- Docs: CUSTOM C++ AND CUDA EXTENSIONS
Kernel func
Source video: P4
-
AT_DISPATCH_FLOATING_TYPESgot passed data type and a name for error prompt. -
scalar_tis used to allow various float types of input data to kernel functiontrilinear_fw_kernel, asAT_DISPATCH_FLOATING_TYPEScan recieve float16, float32, float64.-
Specify sepcific dtype rather than
scalar_tandsize_t:1 2 3 4 5 6trilinear_fw_kernel<<blocks, threads>>( feats.packed_accessor<float, 3, torch::RestrictPtrTraits>(), points.packed_accessor<float, 2, torch::RestrictPtrTraits>(), feat_interp.packed_accessor<float, 2, torch::RestrictPtrTraits>(), var_not_tensor // packed_accessor is only for tensor )
-
-
packed_accesorindicates how to index elements by stating “datatype” (scalar_t) and “number of dimensions” (3) for each input. Andsize_tmeans shape of an index aligned withscalar_t. -
torch::RestrictPtrTraits: Memory is independent to any other variables. -
Kernel
trilinear_fw_kerneldoesn’t return any value (void), with directly changing the memory of output data. Thus, output must be passed. -
__global__means kernel function is called on cpu and excecuted on cuda devices.__host__for functions called on cpu and run on cpu.__devicefor functions called and run both on cuda device.
-
Indexing samples by
nand indexing features byf. -
If threads accessed empty area, program returns.
setup.py
Building CudaExtension: “setup.py”
|
|
- Build and install:
pip install . - Delete failed building history manually: “/home/yi/anaconda3/envs/AIkui/lib/python3.10/site-packages/my_cppcuda_pkg-0.1.dist-info”
test.py
Python function: “test.py”
|
|
title: “watch: CppExt - AI葵 05 | Validate” date: 2023-10-28T12:05:00
To validate if cuda kernel yields correct results, impelement a PyTorch version.
|
|
title: “watch: CppExt - AI葵 06 | Backward” date: 2023-10-28T16:40:00
Source video: Pytorch+cpp/cuda extension 教學 tutorial 6 反向傳播 - English CC -
Compute Partial Derivatives
When loss L comes, the partial derivatives of L w.r.t. every trainable input variable of the function are required.
Trilinear interpolation:
$$ \begin{aligned} f(u,v,w) = (1-u) * [ & (1-v)(1-w)f₁ + v(1-w)f₃ + (1-v)wf₅ + vw f₇ ] \\ + u * [ & (1-v)(1-w)f₂ + v(1-w)f₄ + (1-v)w f₆ + vwf₈ ] \end{aligned} $$
-
u,v,w are coordinates, which are constant (
requires_gradis False). So only vertices features f₁, f₃, f₅, f₇, f₂, f₄, f₆, f₈ need optimizing. -
Given interpolated result
f, their gradients for this operation are:$$ \begin{aligned} &\frac{∂f}{∂f₁} = (1-u)(1-v)(1-w); &\frac{∂f}{∂f₂} &= u(1-v)(1-w); \\ &\frac{∂f}{∂f₃} = (1-u)v(1-w); &\frac{∂f}{∂f₄} &= uv(1-w); \\ &\frac{∂f}{∂f₅} = (1-u)(1-v)w; &\frac{∂f}{∂f₆} &= u(1-v)w; \\ &\frac{∂f}{∂f₇} = (1-u)vw &\frac{∂f}{∂f₈} &= uvw \end{aligned} $$
-
The derivatives of
Lw.r.t. features f₁, f₂, f₃, f₄, f₅, f₆, f₇, f₈ are:$$ \frac{∂L}{∂f} \frac{∂f}{∂f₁}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₂}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₃}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₄}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₅}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₆}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₇}; \quad \frac{∂L}{∂f} \frac{∂f}{∂f₈} $$
Bw Kernel
-
Write host function
trilinear_bw_cubased ontrilinear_fw_cuin “interpolation_kernel.cu”1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24torch::Tensor trilinear_bw_cu( const torch::Tensor dL_dfeat_interp, // Inputs const torch::Tensor feats, const torch::Tensor points ){ const int N = points.size(0); const int F = feats.size(2); torch::Tensor dL_dfeats=torch::empty({N,8,F}, feats.options()); // output data const dim3 threads(16,16); const dim3 blocks((N+threads.x-1)/threads.x, (F+threads.y-1)/threads.y); // Launch kernel function AT_DISPATCH_FLOATING_TYPES(feats.type(), "trilinear_bw_cu", ([&] { trilinear_bw_kernel<scalar_t><<<blocks, threads>>>( dL_dfeat_interp.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(), feats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>(), points.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(), dL_dfeats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>() ); } ) ); return dL_dfeats; } -
Write kernel function
trilinear_bw_kernelbased ontrilinear_fw_kernelin “interpolation_kernel.cu”:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31template <typename scalar_t> __global__ void trilinear_bw_kernel( const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> dL_dfeat_interp, const torch::PackedTensorAccessor<scalar_t, 3, torch::RestrictPtrTraits, size_t> feats, const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> points, torch::PackedTensorAccessor<scalar_t, 3, torch::RestrictPtrTraits, size_t> dL_dfeats ){ const int n = blockIdx.x * blockDim.x + threadIdx.x; const int f = blockIdx.y * blockDim.y + threadIdx.y; if (n >= points.size(0) || f>= feats.size(2)) return; // Define helper variables const scalar_t u = (points[n][0]+1)/2; const scalar_t v = (points[n][1]+1)/2; const scalar_t w = (points[n][2]+1)/2; const scalar_t a = (1-v)*(1-w); const scalar_t b = v*(1-w); const scalar_t c = (1-v)*w; const scalar_t d = v*w; // Compute derivatives dL_dfeats[n][0][f] = dL_dfeat_interp[n][f]*(1-u)*a; dL_dfeats[n][1][f] = dL_dfeat_interp[n][f]*(1-u)*b; dL_dfeats[n][2][f] = dL_dfeat_interp[n][f]*(1-u)*c; dL_dfeats[n][3][f] = dL_dfeat_interp[n][f]*(1-u)*d; dL_dfeats[n][4][f] = dL_dfeat_interp[n][f]*u*a; dL_dfeats[n][5][f] = dL_dfeat_interp[n][f]*u*b; dL_dfeats[n][6][f] = dL_dfeat_interp[n][f]*u*c; dL_dfeats[n][7][f] = dL_dfeat_interp[n][f]*u*d; } -
Add the function signature into header file “include/utils.h”
1 2 3 4 5torch::Tensor trilinear_bw_cu( const torch::Tensor dL_dfeat_interp, const torch::Tensor feats, const torch::Tensor points ); -
Add a cpp function to call the backward method
trilinear_bw_cuin “interpolation.cpp”:1 2 3 4 5 6 7 8 9 10 11torch::Tensor trilinear_interpolate_bw( const torch::Tensor dL_dfeat_interp, const torch::Tensor feats, const torch::Tensor points ){ CHECK_INPUT(dL_dfeat_interp); CHECK_INPUT(feats); CHECK_INPUT(points); return trilinear_bw_cu(dL_dfeat_interp, feats, points); }Give the function
trilinear_interpolate_bwa name in PYBIND as a method of the package:1 2 3 4PYBIND11_MODULE(TORCH_EXTENSION_NAME, m){ m.def("trilinear_interpolate", &trilinear_interpolate); m.def("trilinear_interpolate_bw", &trilinear_interpolate_bw); }
Encapsulate
Wrap forward and backward by a subclass inherited from torch.autograd.Function in “test.py”:
|
|
Notes:
-
The nubmer of return values needs to match the input to forward pass. If some input doesn’t require grad, return a None.
-
ctxis mandatory for storing intermeidate data.
Verify Graident
Test the gradient of backward:
|
|