Code | Arxiv (2307) | ProjPage
Abs & Intro
- Fine-tune the pre-trained text-to-image diffusion model (SD)
- Insert cross-attention blocks between UNet blocks;
- Generate multiple views in parallel using a SD, and fuse multi views by attention;
- Freeze pre-trained weights while training the attention blocks
Solving problems:
- Generating panorama
- Extrapolate one perspective image to a full 360-degree view
Preliminary
MVDiffusion derives from LDM (Latent Diffusion Model¹), which contains 3 modules:
- VAE for transfering the generation process to a latent space,
- denoising model (UNet) for sampling from the distribution of the inputs’ latent codes,
- condition encoder for providing descriptors.
Loss function is similar to original diffusion model: the MSE between original noise and predicted noise, which conditioned on noisy latents, timestep, and featues.
$$L_{LDM} = ∑$$
Convolution layers are insert in each UNet block:
- Feature maps at each level will be added into UNet blocks.

Figure 2
Pipeline
pixel-to-pixel correspondences enable the multi-view consistent generation of panorama and depth2img, because they have homography matrix and projection matrix to determine the matched pixel pairs in two images.
Panorama
Text-conditioned model: generate 8 target images from noise conditioned by per-view text prompts.
-
The final linear layer in CAA blocks are initialized to zero to avoid disrupt the SD’s original capacity.
-
Multiple latents will be predict by UNet from noise images and then restored to images by the pre-trained VAE’s decoder.
Image&Text-conditioned model: generate 7 target images based on 1 condition image and respective text prompts.
-
Based on SD’s impainting modle as it takes 1 condition image.
-
Don’t impaint the condition image by concatenating the noise input with a all-one mask (4 channels in total)
-
Compeletly regenerate the input image by concatenating the noise input with a all-zero mask (4 channels in total)
-
Concatenating all-one and all-zero channel during training make the model learn to apply different processes to condition image and target image.
-
depth2img
This two-stage design is because SD’s impainting modle doesn’t support depth map condition.
- So the Text-conditioned model is reused to generate condition images.
- Then the Image&Text-conditioned model interpolate the two condition images.
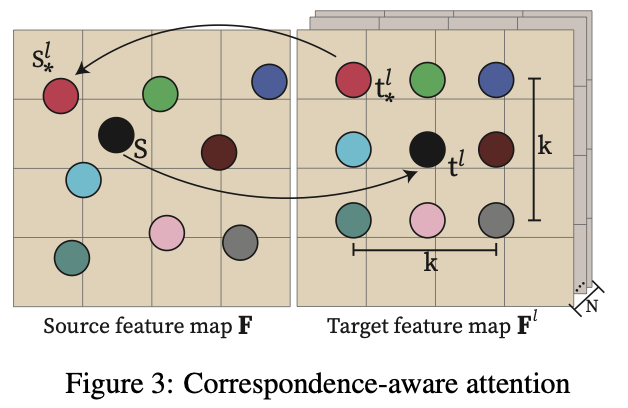
Correspondence-aware attention
Aggregate the features of KxK neighbor pixels on every target feature maps to each pixel their own feature vector.
-
The source pixel $s$ perform positional encoding γ(0)
-
The neighbor pixel $t_*^l$ around the corresponding pixel $t^l$ on the target image $l$ perform position encoding $γ(s_*^l-s)$, which means the neighbor pixel $t_*^l$ need to be warpped back to source feature map to find the distance from $s_*^l$ to the source pixel $s$.
Figure 3